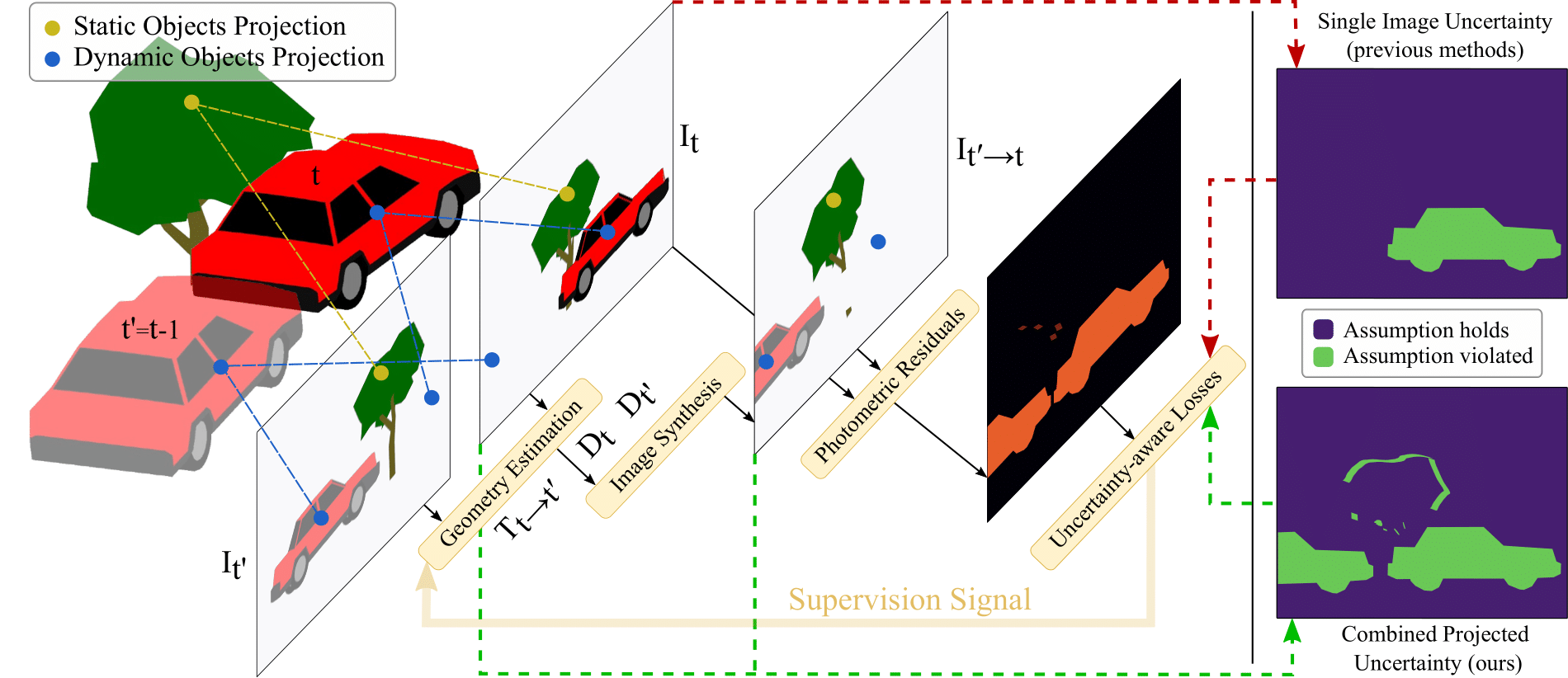

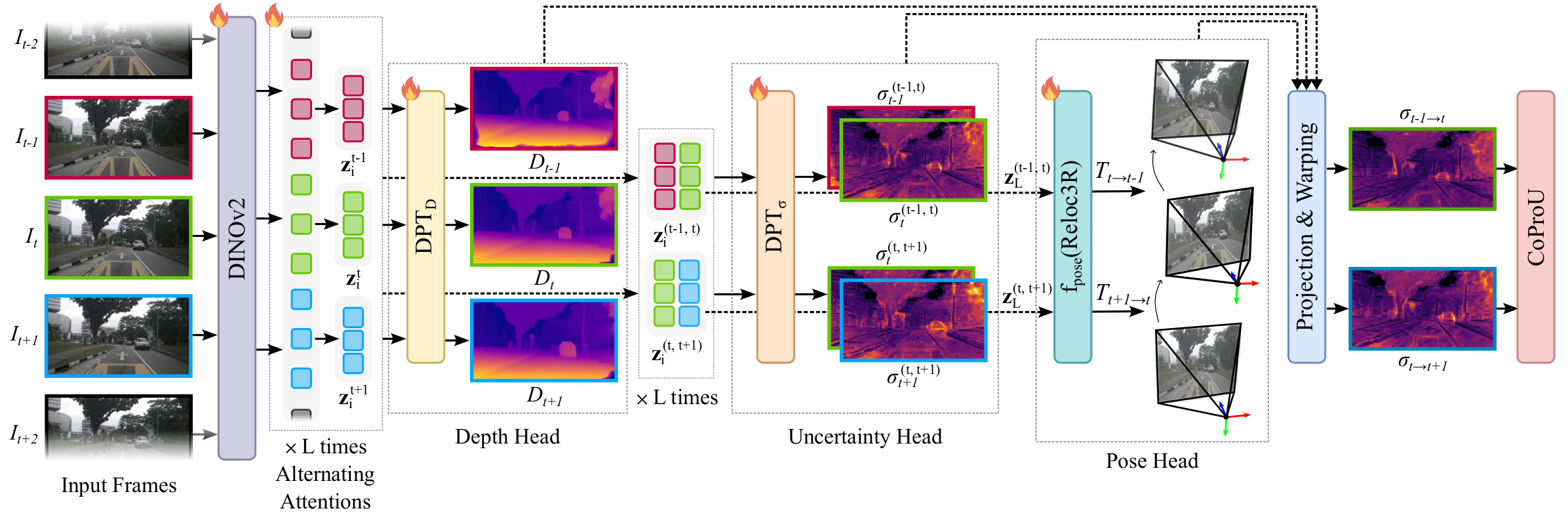
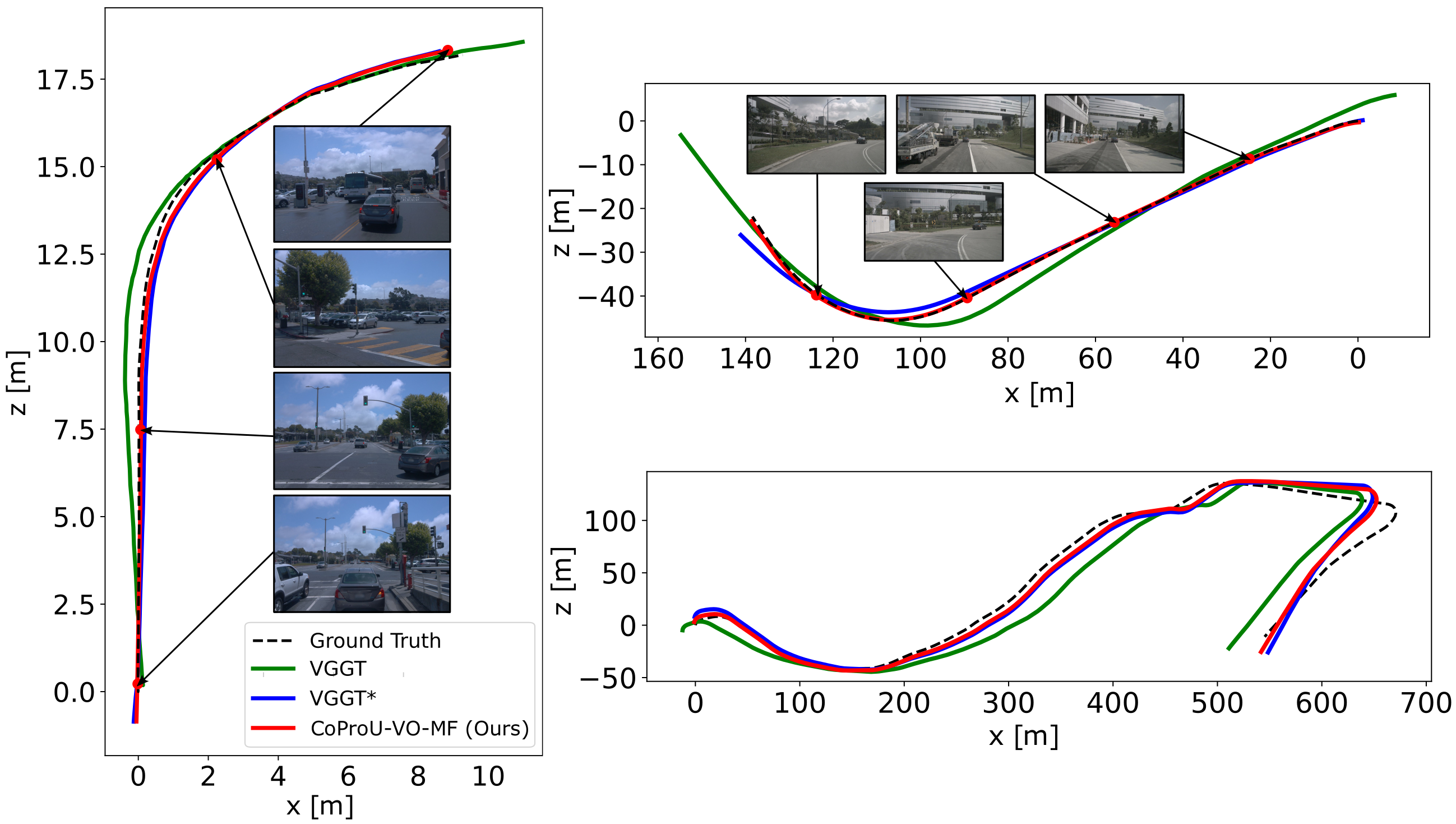
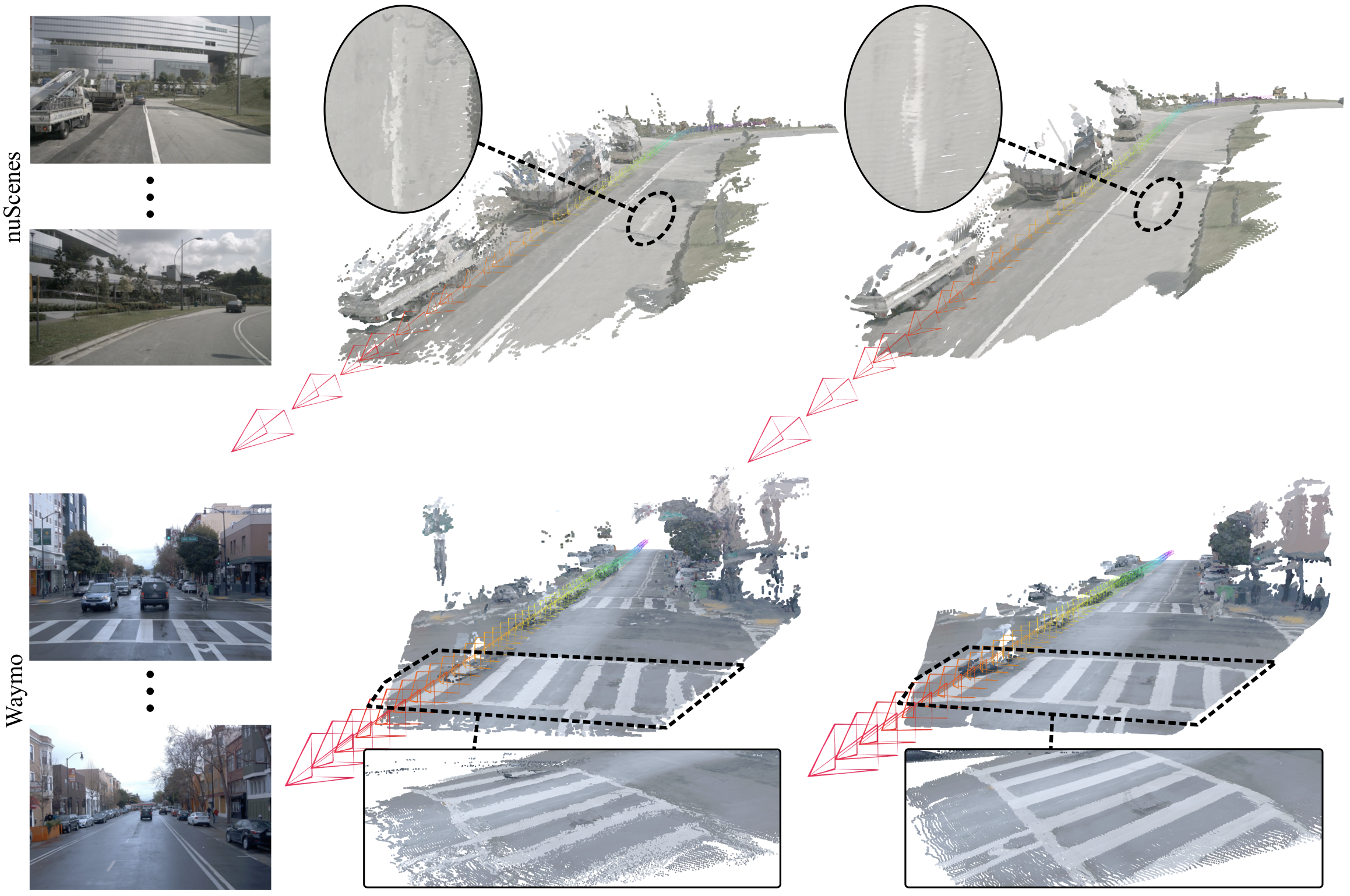

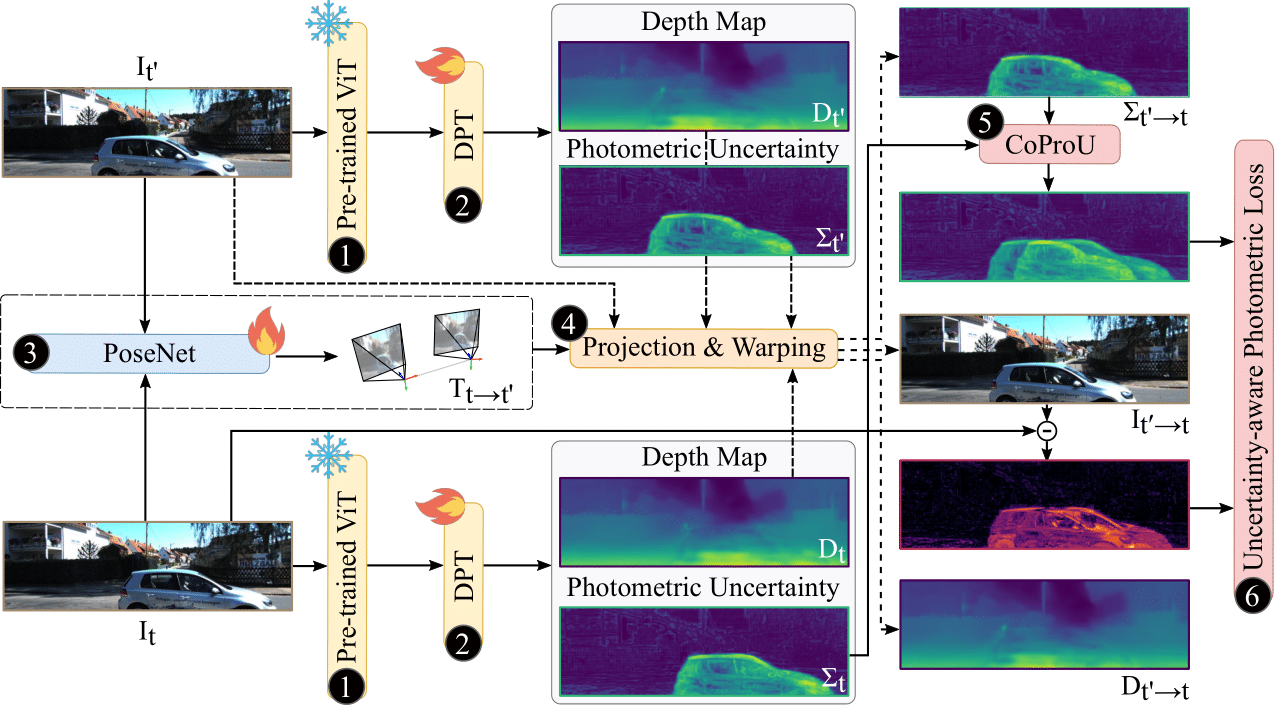

CoProU (Ours)

D3VO - Single Uncertainty

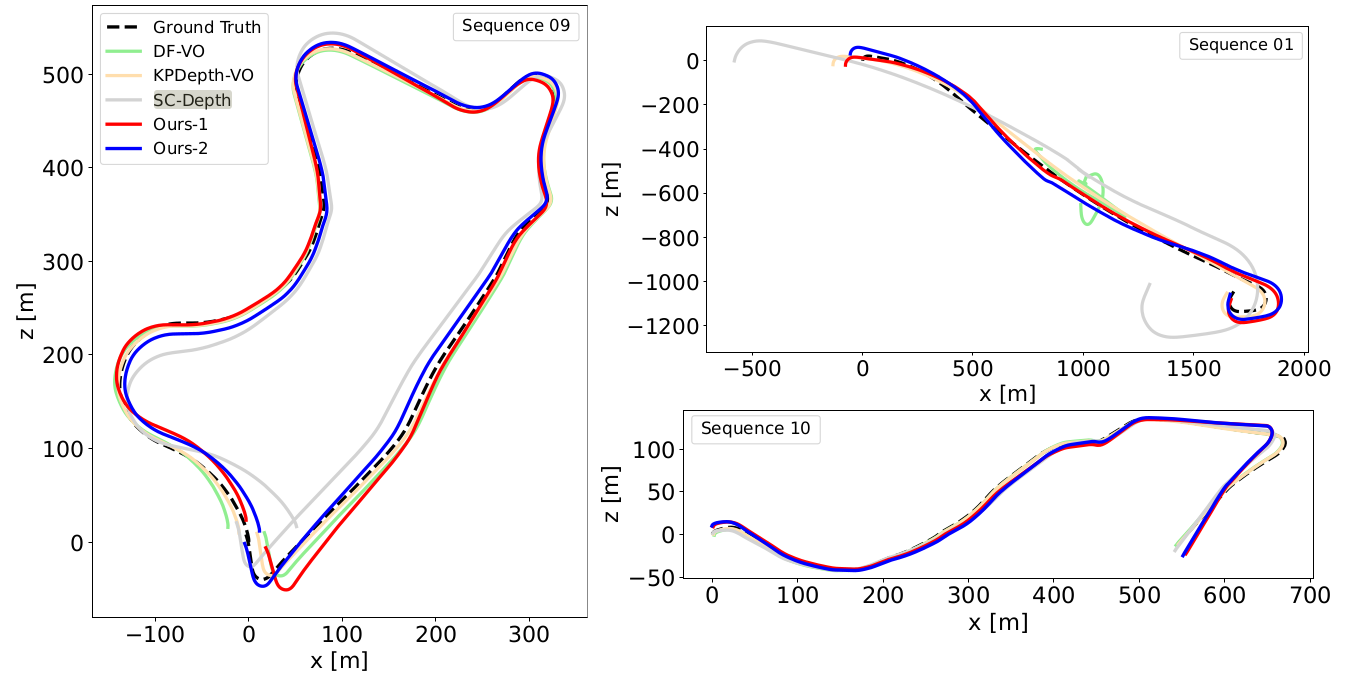
CoProU (Ours)

D3VO - Single Uncertainty



